





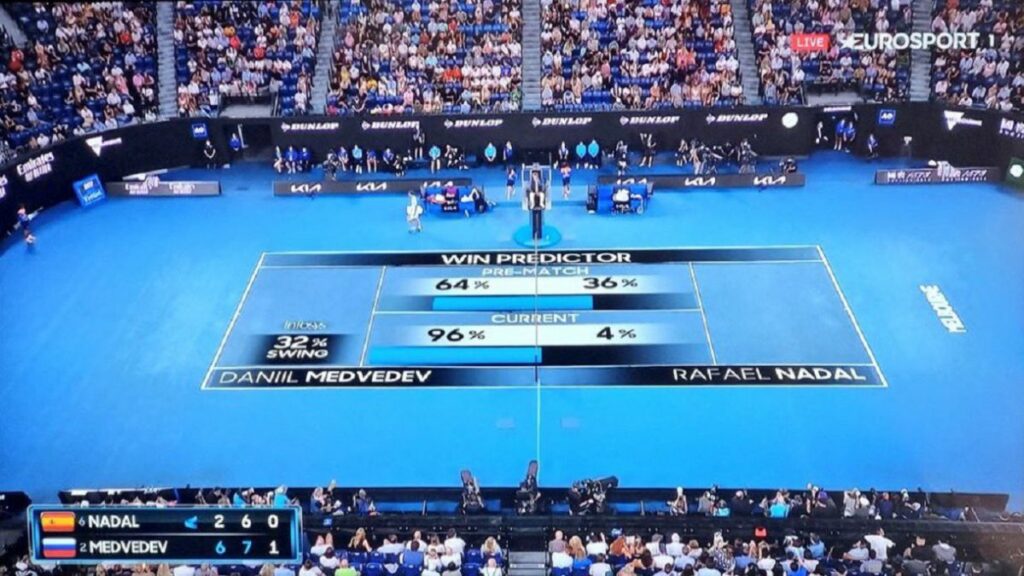
Inicio del tercer set de la final del Abierto de Australia. Daniil Medvedev ha ganado dos sets y se adelanta 0-1 en el tercero. La imagen televisiva muestra sobre la pista la probabilidad de victoria: 96% del ruso, 4% para el español Rafael Nadal. El resto es la historia de una épica remontada y el hito del ‘Grand Slam’ número 21 para el español. Pero, ¿batió Nadal al algoritmo matemático? Varios expertos en analítica de datos aplicada al deporte analizan para EFE las claves.
Ese 4% que el win predictor del torneo australiano daba en aquel momento a una remontada del manacorí –al inicio del partido le otorgaba un 36% de opciones de ganar– ha sido objeto de comentarios jocosos de todo tipo en las redes sociales, todos ellos realizados a posteriori, cuando el tesón del jugador con más grandes torneos de la historia del tenis masculino convirtió un partido casi perdido en un triunfo épico.
Sin embargo, a juzgar por los expertos consultados por EFE, el porcentaje estaba justificado. En 338 partidos disputados por el tenista español en torneos Grand Slam, los cuatro principales del circuito, de 19 situaciones en las que Nadal había comenzado perdiendo 0-2, solo había remontado dos; y en 13 de ellas en las que se enfrentaba a un jugador de los diez primeros del circuito ATP no se había impuesto en ninguna. Hasta el domingo.
Un algoritmo no se bate o se vence. Lo que hace un algoritmo es a partir de información, como el histórico de resultados de Rafa Nadal, ver cómo le ha ido en esa situación. Nadal nunca había ganado en esa situación. ¿Significa eso que un 4% es que no va a ganar un partido? No, sino que ese partido, en esa situación, jugado 100 veces lo habría ganado en 4″, explica a EFE Jesús Lagos, socio de ScoutAnalyst, una consultora que da servicios de datos a clubes de fútbol españoles y europeos.
En la era abierta, desde 1974, solo seis tenistas habían remontado un dos sets en contra en una final de un gran torneo: Bjorn Borg (Roland Garros 1974), Ivan Lendl (Roland Garros 1984), André Agassi (Roland Garros 1999), Gastón Gaudio (Roland Garros 2004), Dominic Thiem (Abierto de EEUU 2020) y Novak Djokovic (Roland Garros 2021).
“Siendo francos, el 4% era muy generoso”, agrega Salva Carmona, consejero delegado de la compañía de analítica especializada en fútbol Driblab, que trabaja con clubes, agentes de jugadores y federaciones. “A partir de ahora, lo que tenemos que pensar todos es si vamos a tener que meter en el modelo de predicción otras variables como el cansancio, cuánto han corrido, o si solo tenemos en cuenta el resultado. Hay cosas que el modelo no tiene en cuenta. Y luego está el factor Nadal, que no es un tenista cualquiera, es un jugador con 21 Grand Slam”, añade.
Para la analista de datos de la agencia de representación de deportistas YouFirst, Sara Carmona, este caso es una muestra de que el dato en el deporte es “un complemento” y no debe tratarse como si fuera una verdad absoluta. “Ese 4% da una información circunstancial, una probabilidad que no tiene por qué cumplirse. Aunque lo normal hubiera sido que Nadal no lograra la victoria, principalmente por la dinámica que el partido llevaba, pero con Nadal hablamos de un fuera de serie. De un animal competitivo con una mente tan trabajada como su juego”, apunta.
CÓMO EXPRIMIR UN 4%
La clave, señala Jesús Lagos, es comprender cómo Nadal consiguió exprimir ese 4%. “La gracia sería encontrar bajo qué patrones ocurre ese 4%. Si es porque metes menos servicios y el rival falla más, por ejemplo. Pero eso en tiempo real es complicado, y ahí la inteligencia artificial aporta más valor”, explica.
El Abierto de Australia analiza sus datos a través de una compañía denominada Game Insight Group, formada por la federación australiana de tenis y la Universidad de Victoria en Melbourne. Además, cuenta en este área con el patrocinio de la consultora tecnológica Infosys, también patrocinadora del circuito ATP, al que ofrece su plataforma tecnológica para la visualización de datos.
Esta empresa reveló recientemente algunos datos que ayudan a entender cómo Nadal exprimió ese 4% de probabilidades. Después de tener una media del 55% de acierto en su primer servicio en los dos primeros sets, en el tercero el campeón español elevó su efectividad con el servicio al 82%. De un 11% de acierto con su derecha en el primer set a un 35% en el cuarto.
Un ejemplo de trabajar con esos datos para maximizar el rendimiento es el equipo de la campeona olímpica y mundial de bádminton Carolina Marín, dirigido por su entrenador Fernando Rivas. “Ellos analizan lo que llama las secuencias, si una jugadora golpea el volante derecha, derecha, izquierda y arriba, cuál es la probabilidad de que ocurra eso, lo que te permite adelantarte y convertirlo casi en una partida de ajedrez”, explica Lagos.

Otro elemento que brilla en el caso de Rafa Nadal es la fortaleza mental. Una clave que, según los expertos, a día de hoy no es posible traducir en datos que se incorporen a un modelo probabilístico. “No se puede meter en el modelo si no hay un proveedor de datos psicológicos, y que yo lo sepa, al menos en fútbol no lo hay. En el fútbol solemos tener en cuenta la idea de jugar en casa o fuera, pero en el tenis siempre juegan fuera. Tampoco se tiene en cuenta el clima, o la calidad del terreno de juego”, apunta Salvador Carmona.
UN GOLPE A UN SECTOR FLORECIENTE
El sector del análisis de datos masivos (Big Data) aplicado al deporte es un negocio floreciente. Según la consultora estadounidense Markets and Markets, estos servicios crecerán un 22% anual hasta sumar un tamaño de mercado superior a los USD 5.200 millones en 2024.
El logro de Rafa Nadal frente a la probabilidad que le asociaba el algoritmo, ¿puede afectar en alguna manera a la credibilidad del sector? “Creo que se va a quedar como un chascarrillo, pero nos hace daño como sector. Lo que ha pasado con Nadal pasa con este tipo de predicciones en el fútbol. Hay empresas que venden a clubes que un jugador va a marcar 25 goles, y no aciertan. Generan mucho ruido y mucha insatisfacción”, comenta Jesús Lagos, de ScoutAnalyst.
Para Salvador Carmona seguramente este caso se use “como arma arrojadiza” contra el sector, pero también genera un interés que puede ayudar a que el público se haga una idea más precisa de qué es la analítica de datos. “Hay mucha sobreinformación, así que habrá gente que será curiosa y leerá sobre la materia”, opina el fundador de Driblab.





{kind=link}